SEO, inferenza, frequenza inversa ed il tesoro nascosto.
A volte cercando una cosa se ne trovano tutt'altre (serendipità?); stavo approfondendo alcuni concetti della Search Engine Optimization e mi sono imbattuto in uno strumento che ha stregato la mia attenzione e che col SEO ha poco a che fare (O forse no? Sembra che questoconcetto di TF/IDF sia sempre stato usato nel definire il pagerank di Google).
Seguitemi e, nonostante un inizio complicato, scoprirete uno strumento utile ai curiosi di tutte le latitudini, soprattutto per chi ha a cuore la cultura ed i libri.Come ben sapere i motori di ricerca si stanno evolvendo; e, tra tutti, Google è quello di gran lunga più frequentato.
Per scoprire come far notare una pagina a Google (è di questo che si occupa la Search Engine Optimization) si devono in qualche modo 'smontare' i meccanismi con i quali Google decide che una certa pagina internet arriva in prima posizione nei risultati ricercando una certa keyword.
Sono passati da parecchio i tempi nei quali era sufficiente scrivere in più punti la stessa keyword perchè google considerasse la pagina 'importante' per quella keyword; oggi si parla di motori semantici e di ricerca per concetti piuttosto che per keyword.
In poche parole: quando un utente fa una ricerca ha in mente di cercare un concetto, non una keyword; se per esempio scrive 'cerco scarpe belle e economiche' il concetto sotteso è che vuole trovare in rete qualche sito che offra bei prodotti a prezzo concorrenziale, non siti che contengano le parole 'cerco scarpe belle e economiche'.
L'utente pone alla rete una domanda con la quale vuole esprimere un concetto; questo è tanto più vero quanto la ricerca si sposta verso i device mobili con i quali è più facile 'parlare', cioè pronunciare direttamente la domanda.
Una volta che Google ha 'capito' il concetto sotteso alla domanda, sia esso espresso in parole o a voce, cercherà nel suo archivo siti che esprimano il concetto stesso, in modo da rispondere alla domanda con una risposta concettualmente coerente, semanticamente sulla stessa linea.
A che serve questa noiosa introduzione? Un attimo e ci arriviamo.
Quando google scandaglia un sito in cerca di concetti passa, obbligatoriamente, attraverso le parole scritte nel sito; da queste desume i concetti. Ciò di cui è 'ghiotto' è di quelle parole che descrivono concetti altamente specifici e non generici, in modo da fornire risposte precise a domande precise.
Ed è nel cercare di capire come Google ritiene importante una pagina nei riguardi di un concetto che mi sono imbattito nell'articolo 7 advanced SEO concept di Cyrus Shepard che introduce il concetto di frequenza inversa dei termini ( TF - IDF term frequency–inverse document frequency) che non misura quante volte la parola appare, ma dà una misura dell'importanza di quella parola rispetto alle aspettative desunte da un enorme mole di documenti.
Ad esempio se compariamo 'abito' con 'abito da cerimonia' all'interno di centinaia di riviste il termine abito sarà generale e 'abito da cerimonia' apparirà meno di frequente ed esprimerà un concetto più specifico.
A questo punto arriva la parte divertente: come facciamo a misurare questa 'importanza'? Dove troviamo un set di documenti abbastanza ampio, rappresentativo della nostra cultura e utile per il nostro scopo?
A questo rispondono
- da una parte Google Books, ovvero il sistema che ha indicizzato 500 miliardi di parole in 5 milioni di libri, un set di documenti diverso dal web e che dà un parametro utile dell'importanza dei termini anche al di fuori della rete internet,
- dall'altra un progetto di culturomics (culturomia? lessicologia computazionale che studia il comportamento umano e gli andamenti culturali tramite analisi quantitative di testi) iniziato col nome di 'bookworm' (stranamente simile al 'verme disiscio ' di Stefano Benni, ma è altra storia) creato da Jean-Baptiste Michel e Erez Aiden di Harvard e Yuan Shen del MIT.
Questo oggetto consente di fare ricerche su 5 milioni di libri a partire dall'800 e consente di visualizzare l'andamento della ricerca su un asse temporale; vediamone qualche esempio di utilizzo.
Se ad esempio traccio la presenza nei libri della parola 'computer' mi aspetto di vederla apparire all'incirca negli anni '60 del 900, per poi aumentare; ecco il grafico che ne traccia la presenza come percentuale relativa nei libri dell'anno:
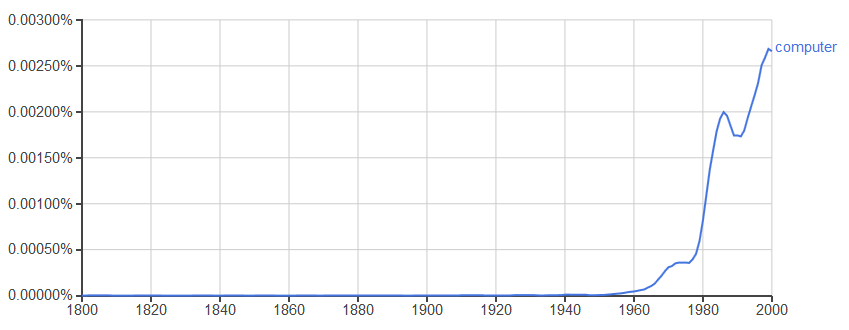
E' possibile tracciare più termini contemporaneamente inserendo una virgola tra loro. Guardate quest'esempio che inserisce altri termini futuribili ed uno invece 'storico', dà parecchio da pensare:
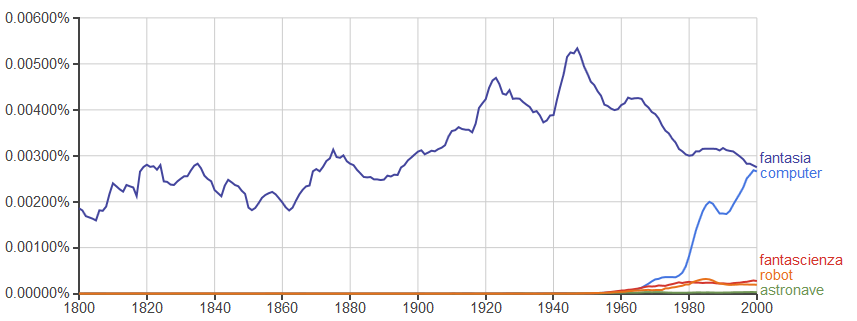
Volendo utilizzare lo strumento in modo più avanzato si possono utilizzare i caratteri jolly, come l'asterisco, ecco cosa capita cercando 'città di *':
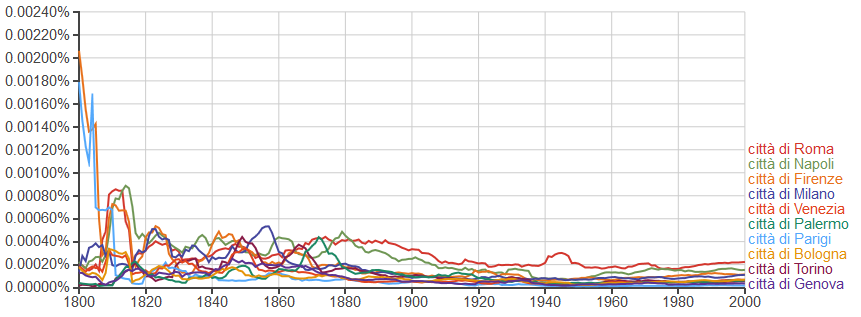
Interessante l'uso nella ricerca del valore grammaticale di un termine; posso ad esempio cercare 'mandato' sia come verbo che come sostantivo, indicando nella ricerca 'mandato_VERB,mandato_NOUN':
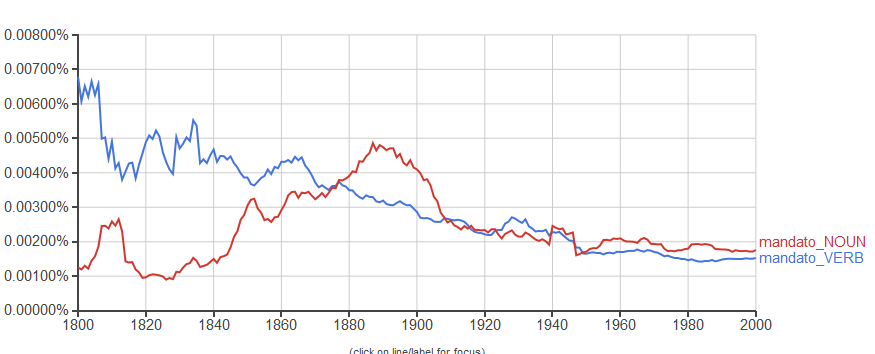
potete divertirvi con altre parti del discorso:
- _NOUN_
- _VERB_
- _ADJ_ aggettivo
- _ADV_ avverbio
- _PRON_ pronome
- _DET_ articolo determinato
- _ADP_ preposizione (o postposizione)
- _NUM_ numerico
- _CONJ_ congiunzione
- _PRT_ particella
Con _START_ analizziamo le frasi che cominciano con un termine; ad esempio possiamo frugrae tra gli incipit scrivendo
_START_ C'era una,_START_ Una volta,_START_ All'inizio,_START_ da subito
otteniamo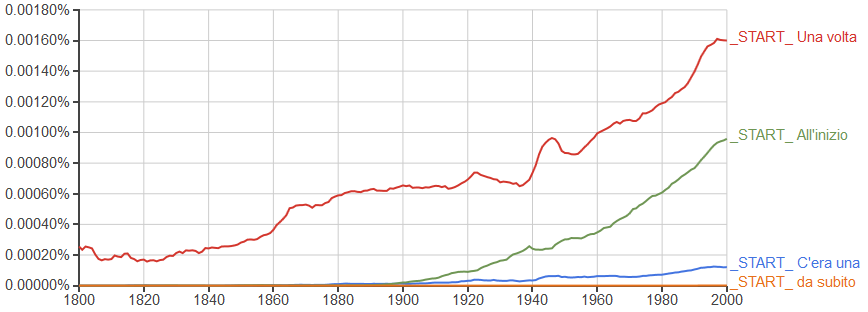
Particolarmente importante ritengo sia l'operatore =>, che mostra la frequenza con cui una parole appare correlata ad un'altra; particolarmente ehmm.. spaventevole è stato tracciare il confronto tra la correlazione tra guerra e morte rispetto a quella tra guerra e vittoria:
guerra=>vittoria,guerra=>morte
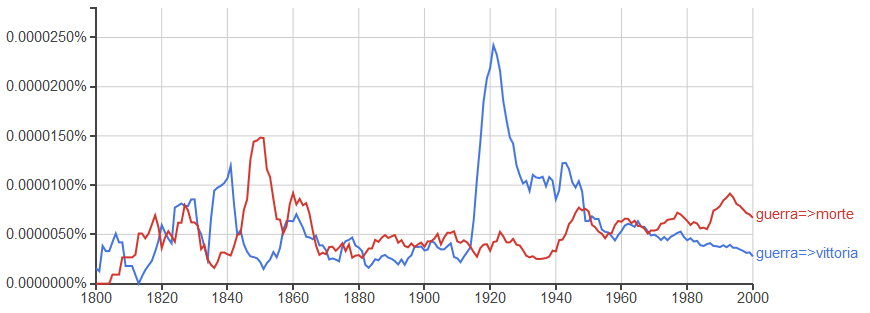
Risulta chiaro l'impeto guerrafondaio degli anni 20-40 del secolo scorso e la corrispondenza tra i massimi di un andamento con i minimi dell'altro.
Possiamo divertirci combinando le cose: con
bere=>*_NOUN
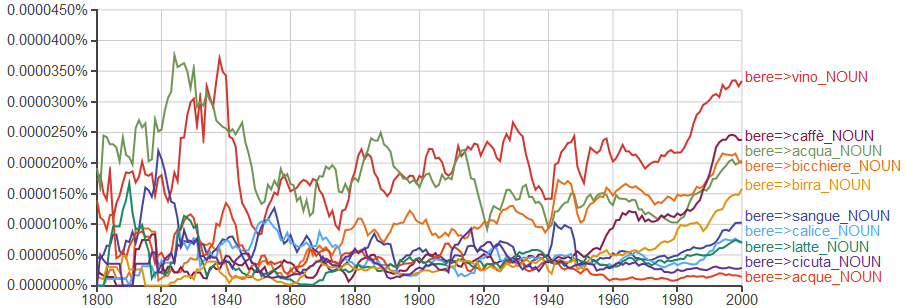
se sostituite il verbo con 'mangiare' potete tracciare le abitudini alimentari; con 'odiare' trovate una correlazione con il precedente grafico della guerra (odiare => nemico), con 'cantare' vedete come siano cambiate le abitudine (da 'te deum' a 'canzone'...)
Ancora: potete utilizzare gli operatori aritmetici e le parentesi, per esempio
(grappa+cognac),assenzio
per tracciare le abitudini dei superalcolici nel tempo: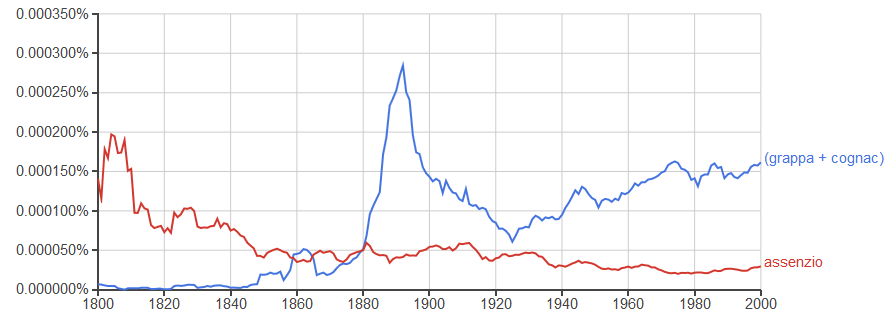
- - -
Altre opzioni ancora sono presenti, le trovate tutte nella pagina delle spiegazioni.
Per me, al di là del SEO, sembra uno strumento utile per soddisfare alcune curiosità sulla cultura dei nostri tempi.
Italo Losero, 24/10/2014