SEO e intelligenza artificiale
Da qualche anno cerco di applicare l'intelligenza artificiale alla ottimizzazione dei siti per i motori di ricerca; in queste note riporto qualche conclusione alla quale sono arrivato.
Innanzitutto definiamo l'intelligenza artificiale; in senso stretto è la modalità di utilizzare la capacità computazionale delle macchine per mimare i meccanismi di apprendimento del cervello, in senso più prosaico è l'applicazione di particolari algoritmi su grandi quantità di dati per estrarne una conoscenza utile a prendere decisioni.
Nella pratica di ottimizzazione dei siti si ha a che fare con l'intelligenza artificiale di Google, che ne esamina le pagine e le indica nei risultati di ricerca per le keyword digitate dall'utente.
Ben lungi dal poter capire quale sia l'algoritmo utilizzato da Google, vista anche la frequenza con la quale varia, possiamo invece definire che l'ordinamento dei risultati di ricerca (la SERP) sia la traccia che è frutto dell'utilizzo dell'algoritmo; come se vedessimo le orme lasciate nella neve da qualcuno, da esse possiamo cercare di capire la direzione e qualche indizio in più che sia utile per l'ottimizzazione dei siti.
Per la pratica SEO le azioni che possono essere messe in atto possono riguardare in linea di massima 5 attività principali:
• Intervenire sulla correttezza del codice strettamente legato alla pratica SEO (ottimizzazione titoli, descrizione, url, etc)
• Scrivere contenuti nel sito
• Intervenire sui social per portare utenti sul sito
• Intervenire con link e backlink, per aumentare la rete di collegamenti
• Eseguire interventi tecnologici di ampliamento delle modalità di comunicazione del sito (pagine AMP, dati strutturati, etc)
Utilizzare l'intelligenza artificiale per migliorare le pratiche SEO
Nel metodo utilizzato innanzitutto si procede a definire una keyword, o meglio, una serie di keyword che fanno parte dell'obbiettivo di miglioramento; nella pratica ho cercato di utilizzare fasci di keyword, semanticamente omologhe, per riuscire ad avere risultati che non riguardino la singola keyword ma piuttosto il suo significato; normalmente ho utilizzato una cinquantina di keyword.
Per ognuna di esse si estrae il risultato dei motori di ricerca fino ad una certa posizione; per esempio fino alla cinquantesima posizione. In questo caso si ottengono 2500 risultati, alcuni dei quali duplicati, potremmo per esempio ottenere circa 2000 risultati univoci.
Già questa serie di dati ci può essere utile; per ognuno dei 2000 risultati possiamo ricavare le caratteristiche di come appaiono nelle pagine di Google ricavando indicazioni sul titolo, sull'url, sulla descrizione, registrando di ognuno, per esempio, testo e numero di caratteri. Avremmo in questo caso sette dati per ogni risultato: la posizione più testo e lunghezza di titolo, url e descrizione; otteniamo così un database di 2000 righe per sette colonne, cioè 14000 dati.
Questo primo set di dati ottenuto non è molto grande, ma su questo possono essere già effettuate alcune analisi.
A questo punto è necessario chiarire il concetto di supervisione dei dati. Nell'apprendimento artificiale i set di dati a disposizione si dividono in due categorie:
1. Supervisionati, quando ad ogni dato (ogni riga del database precedente) viene associata una etichetta inserita con meccanismi esterni al set di dati (per esempio, se etichettassimo a mano ogni risultato con una etichetta del tipo 'blog','sito di notizie', 'aggregatore' etc. avremmo un set di dati supervisionato.
2. Non supervisionato, quando i dati sono presi 'as is', e da essi si cerca di estrarre il pattern che lega i dati tra loro.
Nel nostro caso siamo in una via di mezzo: si tratta di un insieme di dati semi-supervisionato, perché ad ogni dato associamo automaticamente una caratteristica fissa che è la posizione assunta nella SERP; è una caratteristica univoca di ogni riga del nostro database che, vedremo, sarà molto utile in seguito.
Una prima analisi: clusterizzazione dei dati
Il clustering dei dati è una forma di analisi multivariata dei dati che consente di raggruppare i dati in gruppi omogenei per caratteristiche.
Applicando tecniche di clustering ai dati (in questo caso l'algoritmo utilizzato è K-means) e rappresentandoli su una matrice bidimensionale si può ottenere questo risultato: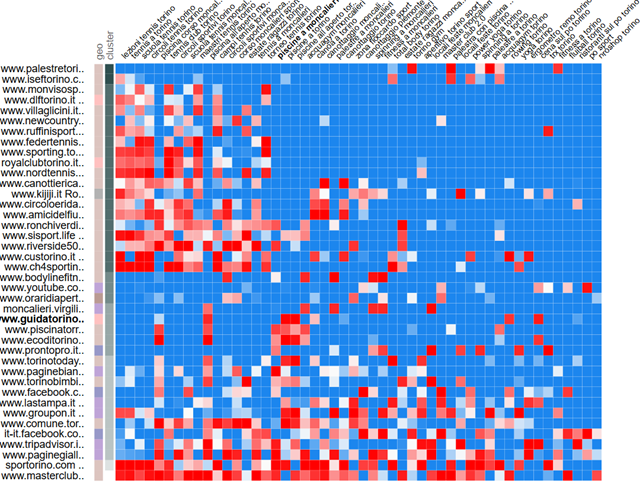
Diagramma visible a : http://amp.pharm.mssm.edu/clustergrammer/viz_sim_mats/5ad596c8b119f01e4809ef93/clutergrammer_positions.txt
La colonna 'cluster', in seconda posizione, indica in scala di grigio il cluster di appartenenza. Il colore indica la posizione media del dominio sulla riga per la keyword della colonna (rosso=prime posizioni, blu=fine SERP). Utilizzando opportunamente questi dati è possibile per l'analista SEO confrontare per gruppi omogenei i posizionamenti, verificando quei competitor che effettivamente si posizionano in modo concorrenziale. Questa un'altra rappresentazione, utilizzando K-medoids: 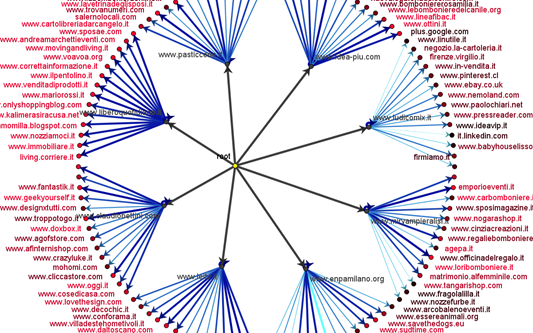
Altri set di dati
Questo modello di clusterizzazione sui dati delle SERP come analisi multivariata non è intelligenza artificiale, ma semplice applicazione statistica al primo set di dati ottenuti.
Per effettuare analisi più complesse vengono ricercate basi di dati più complesse:
Ampliando la base dati: analizzando ognuna delle pagine indicizzate dalle SERP e estraendone alcuni parametri quali lunghezza della pagina, indice di leggibilità, presenza di link ai social, posizione media su Alexa etc; in totale negli esperimenti fatti vengono estratti una quarantina di parametri, sommandoli a quelli precedenti ed ottenendo un set di dati di 2000*(7+40)= 94000
Costruendo un grafo di rete: Ricavando da ogni pagina i link presenti e costruendo un grafo di rete; se, ad esempio, ogni pagina ha mediamente 10 link all'interno si ottiene un grafo di rete con 2000*10=20000 nodi
Costruendo un corpus documentale: ricavando il testo della pagina indicizzata, trasformandolo in un documento a sé da inserire in un corpus di documenti sul quale effettuare analisi lessicali
Utilizzando 56 keyword a profondità 50 in SERP, questi sono i valori dei set di dati che si ottengono: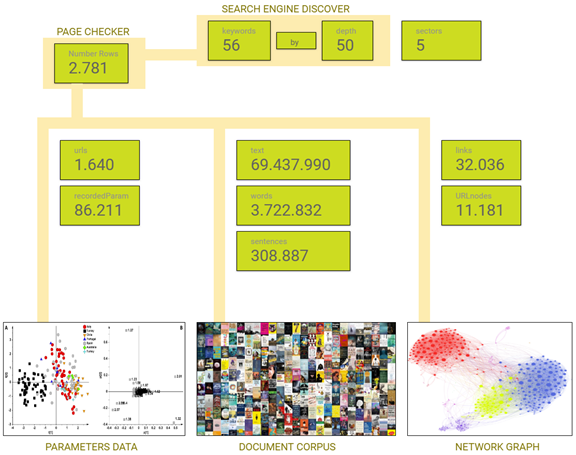
Con questi dati possiamo indagare più a fondo l'universo rappresentato dai risultati del motore di ricerca per le keyword assegnate, in modo da ricostruire dalle 'orme' di Google parte dei parametri che ne regolano il comportamento.
Indagini sulla base dati: analisi di correlazione.
I circa 94000 (86211 nel caso riportato) parametri che descrivono le 2000 (1640) pagine indicizzate vengono messi in correlazione con il posizionamento; se essa è fortemente positiva (misurata con l'indice di Pearson, da +1 a -1) indica che il parametro preso in considerazione è correlato con la posizione, cioè al crescere di quel parametro corrisponde un miglioramento del posizionamento.
Ecco un esempio parziale dei dati ottenuti: 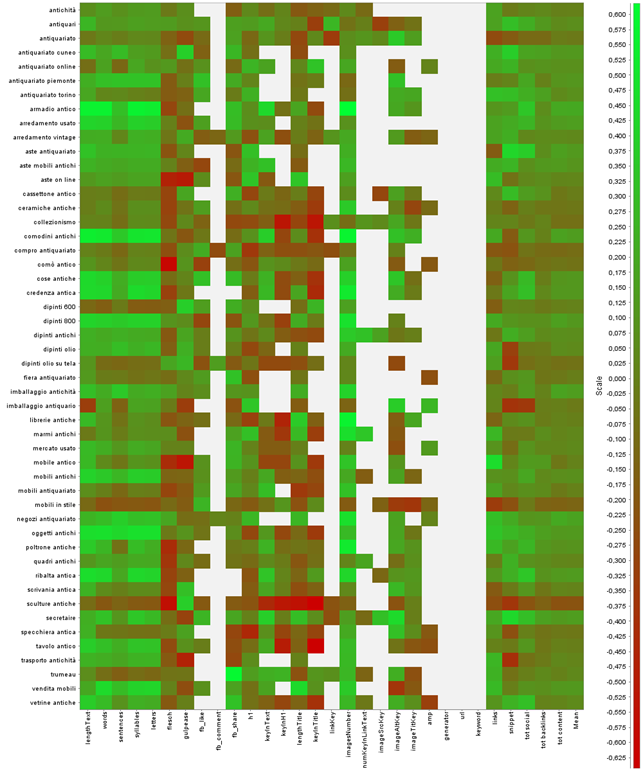
Il colore verde indica una correlazione positiva; da questo diagramma si può vedere, per esempio, che per la keyword 'poltrone antiche' il numero di immagini (imagesNumber) è in correlazione con il posizionamento.
A questo punto raggruppando i parametri che riguardano una delle specifiche azioni di miglioramento prima descritte (ad esempio tutti i parametri 'social') possiamo ottenere una utile indicazioni su quali siano le azioni più utili per promuovere la singola keyword; se, ancora, si raggruppandole keyword per significato semantico si ottiene un utile diagramma che indica l'importanza dell'azione di miglioramento a seconda del settore semantico.
Ecco un esempio: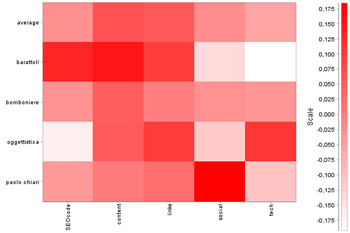
Ogni colonna rappresenta una azione, ogni riga un settore semantico (al quale corrispondono più keyword, ad esempio al settore 'bomboniere' appartiene 'bomboniere nozze', 'bomboniere laurea', 'bomboniera originale'…). Il colore rosso indica una correlazione mediamente positiva.
La prima riga indica la media totale, che ci dice che in generale è bene insistere sui contenuti e su link/backlinks.
Le righe successive ci indicano, ad esempio che per scrivere contenuti 'barattoli' è meglio correlato con il posizionamento degli altri settori, quindi quello in cui primariamente è bene impiegare le risorse redazionali; chiare indicazioni vengono per il 'social' dove il settore 'branded' risulta più importante (il nome è un brand). Il settore delle tecnologie (pagine AMP, dati strutturati) è di gran lunga più importante nel caso si voglia insistere sull'oggettistica.
Molte altre indagini possono essere effettuate su questa base dati; quelle mostrate sono indagini di correlazione siamo cioè ampiamente nell'ambito della statistica, anche se alcuni di questi metodi vengono da alcuni considerati come intelligenza artificiale.
Sono più vicini al concetto di intelligenza artificiale soprattutto quando queste indagini vengono svolte real time per esempio durante le navigazioni di utente, per definire ad esempio a seconda della ricerca che ha fatto sul sito quali risultati fornirgli. In questo caso si costruisce la base di dati per istruire il sistema, in base a questa base vengono realizzate le correlazioni e l'utente indirizzato verso la direzione più profittevole alla conversione; in questo caso siamo un po' usciti dall'ambito SEO per passare alla ottimizzazione delle conversioni.
Analisi dei grafi di rete
Con il grafo di rete costruito utilizzando tutti i link presenti nelle 2000 pagine possiamo ricostruire la 'idea' che Google può avere dei collegamenti che riguardano le keyword. Il grafo, in sé, potrebbe essere poco utile alla visualizzazione diretta:
Ma portando a fattor comune il nome di dominio possiamo ottenere due grafici interessanti: IN/OUT e HUB/AUTH.
Il primo ci indica quanti collegamenti i siti hanno in ingresso o in uscita (blu/rosso), e ci è utile per avere una idea di quali siano i maggiori player nel settore: 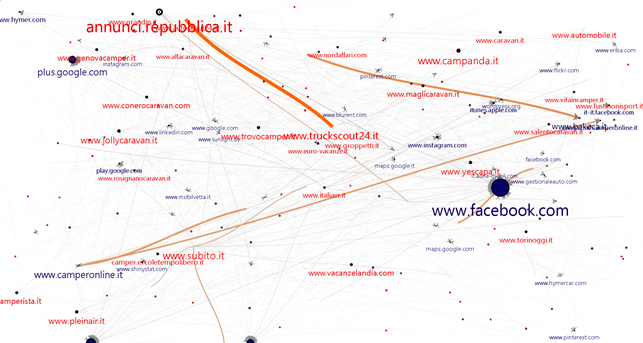
Il secondo, più interessante, lo otteniamo utilizzando la matematica dei grafi analizzando il valore dei nodi come HUB (verde), cioè siti che linkano risorse autorevoli, e come AUTH (viola), cioè risorse autorevoli in rete. 
Le indicazioni interessanti dalla matematica dei grafi le possiamo utilizzare in questo modo:
I siti HUB sono quelli che hanno link verso risorse importante; sono quindi quelli che meglio si candidano per ospitare i backlink verso il nostro sito, quelli in cui è più utile investire in pubblicità; possono essere utilizzati per valutare la rilevanza di un investimento nel settore
I siti AUTH sono quelli da linkare per essere presenti in modo importante nel grafo di rete; sono quelli da utilizzare nelle linkografie da abbinare ai contenuti.
Anche in questo caso vengono applicate ai grafi di rete matematica e statistica; non siamo ancora nell'ambito dell'intelligenza artificiale anche se i grafi di rete potrebbero essere esplorati anche con metodi più vicini alla IA.
Analisi del corpus dei documenti.
Con il corpus di documenti si può procedere ad alcune interessanti operazioni, si può cominciare con i diversi tipi di frequenza e di metodi per definire l'importanza delle parole nel contesto; in particolare utilizzando la frequenza assoluta, il peso TD/IDF e il coefficiente Chi square e correlandoli con il posizionamento si possono ottenere quelle parole che sono più utilizzate nei contenuti che meglio si posizionano.
Ad un livello più complesso si può affrontare l'analisi semantica dei contenuti con algoritmi NLP (natural language processing) tipo LDA (latent dirichlet allocation) che è un modello statistico generativo non supervisionato che consente di estrarre un certo numero di argomenti dal corpus dei documenti.
Ciò significa che alla fine della elaborazione l'algoritmo
• individuerà un numero prefissato di argomenti (per esempio 10),
• individuerà per ogni argomento un certo numero di parole che lo definiscono
• assegnerà ad ogni documento l'appartenenza relativa ad uno o più argomenti
In questo primo esempio una tabella rappresenta gli argomenti individuati nel corpus(10) ognuno seguito dal numero di occorrenze e descritto da dieci parole:
topic_0 119 cookie, vendita, appartamento, locali, informazioni, sito, piano, email, terze, parti
topic_1 259 appartamenti, vendita, appartamento, mare, villa, prezzo, case, camere, vista, piã¹
topic_2 139 napoli, appartamento, locali, vendita, seguo, appartamenti, affitto, proprietã, agenzia, immobili
topic_3 94 affitto, annunci, vendita, appartamento, affitti, case, appartamenti, annuncio, milano, privato
topic_4 93 �å, �â€, �ã, �â, ��, pisos, idealista, ��â€, ��â, perimeterx
topic_5 174 letto, appartamento, camere, posti, centro, ospiti, camera, bagni, recensioni, vacanze
topic_6 124 milano, appartamento, vendita, affitto, zona, locali, provincia, bilocale, contatta, dettagli
topic_7 295 dati, vendita, più, unicredit, immobiliare, subito, vendere, servizi, puã², personali
topic_8 170 piano, appartamento, zona, bagno, cucina, locali, ingresso, composto, letto, camere
topic_9 118 roma, vendita, affitto, appartamenti, appartamento, annunci, immobiliari, bilocale, immobili, locali
Ecco un altro esempio grafico; in questo caso il corpus documentale è stato diviso in venti argomenti (topic_0--- topic_19). 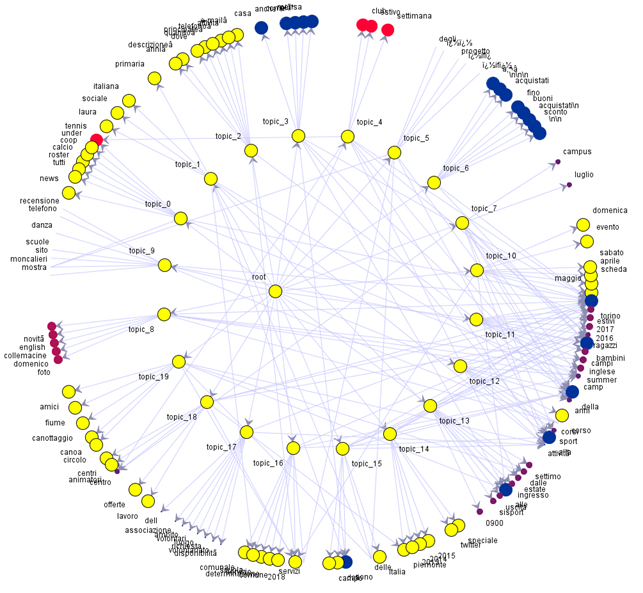
Da un 'root' ideale, utilizzato per la rappresentazione radiale, si dipartono i venti argomenti; da ognuno di essi partono le frecce verso le dieci keyword che descrivono l'argomento. In questa rappresentazione grandezza e colore dei pallini sono utilizzati per indicare il livello di importanza delle parole. A questo punto si possono raccogliere a fattor comune i domini, verificare quale sia l'argomento al quale appartiene con maggior frequenza il dominio, e visualizzare un grafico di questo tipo: 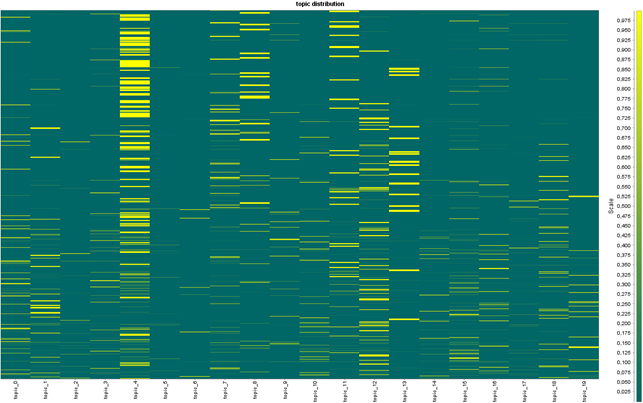
Ogni riga di questa heatmap rappresenta un dominio; quando la corrispondenza con la colonna va verso il giallo vuol dire che il dominio è definito soprattutto dall'argomento di quella colonna, in questo caso molti domini appartengono al topic_4.
I domini sono inseriti a partire dai meglio posizionati (in alto) verso quelli meno bene posizionati( in basso).
Per il SEO non sono molto importanti gli argomenti come topic_11 o topic_12 perché, benché siano diffusi, lo sono uniformemente lungo le SERP; molto più interessanti quelli come topic_8 o topic_4 perché la loro presenza è maggiore nei domini meglio posizionati.
La tabella di correlazione dei domini ci fornisce questa informazione:
indice di Pearson / topic
0.28 topic_4
0.17 topic_8
0.11 topic_11
0.1 topic_13
0.07 topic_7
-0.05 topic_17
-0.06 topic_5
-0.06 topic_9
-0.07 topic_6
-0.07 topic_3
In questo caso il suggerimento a chi si occupa di contenuti è quello di utilizzare soprattuto gli argomenti definiti dalle parole presenti in topic_4 e topic_8.
Ecco il dettaglio delle keyword in questo caso: 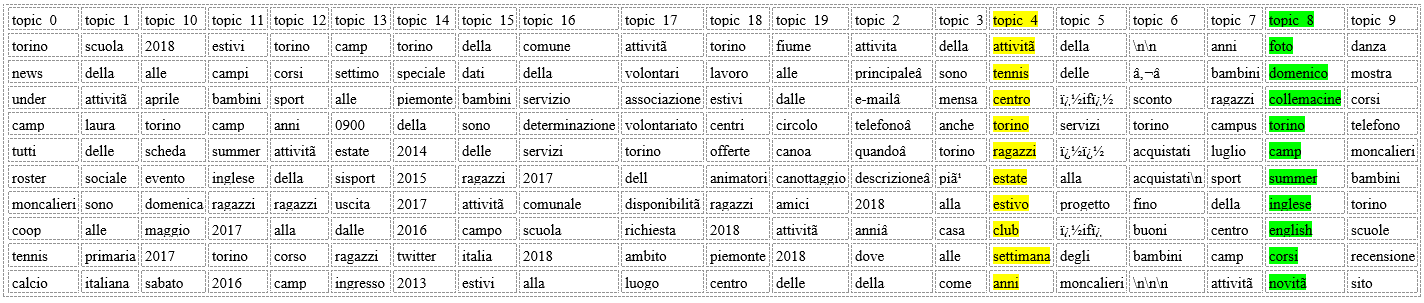
Naturalmente si può precedere ad una lemmatizzazione dei termini per ottenere solo i sostantivi, aggettivi o verbi.
Deep learnings: wordVectors
A questo punto si tratta di 'capire' ciò che è presente nel corpus e di proporre ai redattori di contenuti un estratto dei siti meglio posizionati, indicando loro come meglio procedere nella redazione dei contenuti.
Il lavoro qui descritto viene ripreso per ogni settore semantico, ovvero per ogni fascio di keyword omogeneo per significato.
Dapprima si procede alla ricerca di quelle che sono le keyword più importanti nei documenti presenti nei documenti meglio posizionati; si scelgono solo i documenti che sono stati indicizzati per le keyword di settore nelle prime x (10) posizioni.
Su questo corpus opportunamente preparato e preprocessato si utilizzano algoritmi (tf/idf, keygraph) per estrarre le keyword più importanti; ne riporto qui un esempio in tagcloud:
Sul corpus di documenti si lancia l'algoritmo word2vec per ottenere i cosiddetti word embeddings, cioè una rappresentazione vettoriale di ogni parola che ne definisce i rapporti con tutte le altre.
Tramite matematica matriciale si confrontano i vettori delle keywords prima definite con tutte le parole trovate nel corpus, estraendo tutte quelle che hanno significato simile, o che sono collegate. Si procede in seguito ad una lemmatizzazione ottenendo in questo modo, e per ogni keyword, l'elenco dei sinonimi, sostantivi, verbi, aggettivi, avverbi e nomi geografici correlati.
Si procede inoltre ad un confronto matriciale tra i word embeddings in cui sono presenti le keyword ricercate e tutti i risultati delle ricerche (qualsiasi sia il settore) per trovare l'elenco dei documenti/link che contengono gli stessi contenuti a livello di semantica.
Questo consente, insieme alle analisi precedenti, di produrre un documento finale per i redattori nel quale, per ogni settore semantico affrontato, si definiscono:
1. le caratteristiche tecniche del documento da creare, in termini di numero di parole, immagini, leggibilità, etc. a seconda dei risultati dell'analisi di correlazione
2. i principali argomenti da affrontare (dall'analisi dei topics)
3. la linkografia da utilizzare (dal deep learning e dall'analisi dei grafi di rete) e i link dai quali prendere spunto
4. le parole da utilizzare, affiancate dai loro sinonimi e dalle parti del discorso correlate (di qui alla creazione di frasi automatica il passo è breve), con un grafico che ne spiega i rapporti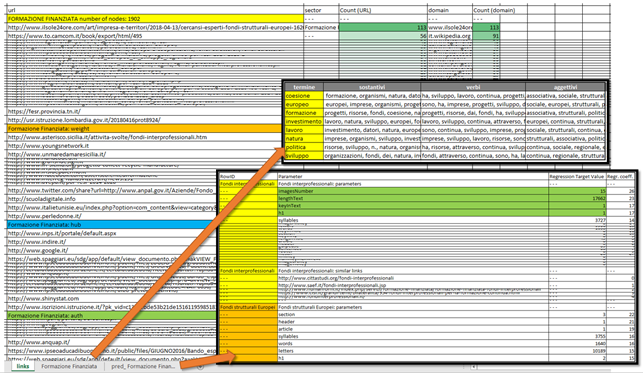
Questo è un esempio di uno dei file prodotti con le indicazioni per i contenuti.
Conclusioni
I metodi descritti in questo documento sono stati variamente utilizzati nel corso degli ultimi anno nella sperimentazione di modalità di ottimizzazione dei siti per i motori di ricerca innovative. L'intelligenza artificiale offre metodi per indagare grandi moli di dati, grafi di rete e corpus documentali che rappresentano una indagine nella rete per l'argomento affrontato, consentendo di estrarre le informazioni indispensabili per una ottimizzazione DEI SITI che vada al di là delle pratiche usuali, utilizzando metodi scientifici per ottenere conoscenza di rete e utili indicazioni di miglioramento.