Intelligenza artificiale applicata nelle aziende: smart inbox
In questo articolo viene descritta una applicazione della intelligenza artificiale per risolvere un problema diffuso nelle aziende: l'inbox overload.
Abbiamo un problema: troppe email di richiesta preventivi.
In questo caso l'inbox overload consiste nell'avere troppe email alle quali dover rispondere; si tratta di richieste di preventivo per l'esecuzione di lavori nell'ambito dello stampaggio.
Data la complessità della materia, la risposta ad ogni email richiede un importante impiego di risorse e tempo e di conseguenza non è possibile rispondere a tutte le richieste. Si deve operare quindi una scelta per decidere a quali email rispondere e a quali no; al di là di una esperienza personale di chi 'subodora' quali siano le richieste 'fortunate' le cui risposte genereranno un successo di business, non esiste in azienda un metodo oggettivo per definire le priorità con le quali rispondere.
La committenza richiede la possibilità di sviluppare un sistema di intelligenza artificiale che 'scopra' o 'preveda' quali saranno le email fortunate, la cui risposta genererà con la massima probabilità un successo commerciale.
Utilizzando una metafora visiva il sistema di intelligenza artificiale potrebbe essere paragonato ad un paio di occhiali che permettano di distinguere le email di richiesta più o meno fortunate.
La soluzione a questo problema passerà attraverso diverse fasi:
- la raccolta dei dati necessari
- un primo addestramento 'meccanico' del sistema
- l'addestramento di un motore di intelligenza artificiale
- la rivincita dell'umano: correzioni
- l'espansione utilizzando algoritmi semantici
- l'espansione utilizzando dati esterni all'azienda
Inbox overload: la raccolta dei dati
L'intelligenza artificiale si nutre di dati dalla cui qualità dipende il successo dell'intero sistema.In questa prima fase si collezionano i dati delle email: mittente, destinatario/i, oggetto, corpo del messaggio e qualsiasi altro dato (presenza di allegati, di immagini, ecc) direttamente legato alla email si possa ricavare. Ci si può rivolgere direttamente al server che riceve le email oppure costruire un sistema che le estragga dal client che le riceve; nel caso descritto è stato utilizzata questa seconda modalità per la costruzione del prototipo.
I dati delle email vengono utilizzati per collegare il CRM aziendale; dall'indirizzo email del mittente o dal nome del dominio si cerca di risalire all'eventuale cliente già presente in database. In questa fase, quindi, verranno escluse tutte quelle email che non appartengono a clienti dell'azienda; vedremo che sono nella fase finale del sistema potremo andare ad analizzare anche queste.
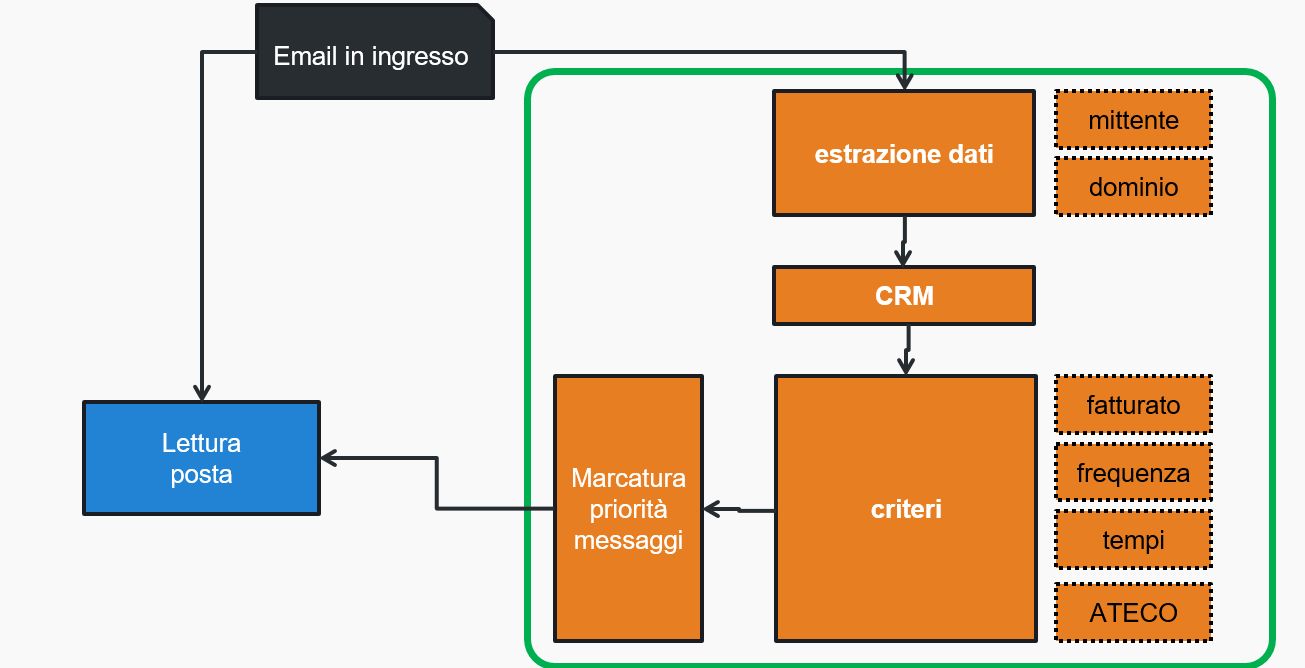
Fase 2: marcatura meccanica dei messaggi
Dopo avere effettuato questo collegamento abbiamo a disposizione, per ogni email collegabile, i dati relativi all'azienda; nello schema vediamo ad esempio il fatturato, la frequenza degli ordini, i tempi di pagamento, il codice ATECO; a questi vengono aggiunti tutti i campi necessari a costruire un primo criterio di classificazione, dando una scala di priorita relativa a questi primi dati; verranno indicate con una maggiore priorità quelle email ricevute da aziende con cui si è già avuto un rapporto commerciale positivo, che abbiano relaizzato un buon fatturato, una buona frequenza di ordini e corretti tempi di pagamento; con questi criteri si potrà effettuare una prima marcatura 'meccanica' dei messaggi con la loro relativa priorità.A questo punto devo fare una constatazione; in tutte le aziende in cui si vogliono inserire sistemi di intelligenza artificiale è necessario, come in questo caso, organizzare e sistematizzare i dati. Ben prima di avere gli effetti positivi dei motori di i.a., già a questo punto si ottengono grandi vantaggi; in alcuni casi la scoperta di questi vantaggi finisce per ritardare l'applicazione dei sistemi più 'intelligenti' proprio perchè si scoprono dati sufficientemente sorprendenti da voler insistere nella fase 'meccanica' piuttosto che spingersi alla fase 'intelligente'.
Attraverso questa marcatura della priorità dei messaggi il personale incaricato comincia ad avere un primo contatto con il sistema, utilizzando le indicazioni di priorità e notando quando queste hanno effettivamente una effettiva utilità e quando invece la priorità assegnata dal sistema 'meccanico' non risulta effettiva; sarà in seguito una indicazione utilissima.
L'operazione di marcatura dei messaggi viene ripetuta per ogni email ricevuta; dopo un certo periodo si avranno a disposizione alcune decine di migliaia di email 'marcate' sulle quali può essere eseguito il passo successivo: l'inserimento di un motore di intelligenza artificiale.
Fase 3: addestramento del motore di intelligenza artificiale
Abbiamo a disposizione a questo punto un insieme di dati come in una tabella dove ogni riga rappresenta una email, ed ogni colonna tutti i campi ad essa connessi, sia quelli più strettamente relativi alle email che quelli dell'azienda ad essa collegata (fatturato, etc) che abbiamo utilizzato per la marcatura meccanica.
Oltre a questi dati viene utilizzato il CRM per aggiungere tutti i campi che ci mette a disposizione; per esempio l'indirizzo dell'azienda, il numero di dipendenti, e qualsiasi altro dato dell'azienda che il CRM possa esporre.
Il nostro scopo è addestrare un motore di intelligenza artificiale perchè da questi dati ed in base alla marcatura meccanica precedente possa 'predire' le nuove marcature 'intelligenti' delle email.
Nella marcatura meccanica i dati sono stati utilizzati secondo un algoritmo tradizionale; per esempio è stato dato un valore di importanza del 100% per una mail con massimo fatturato tra i clienti, massimo numero di ordini, migliore modalità di pagamento impostando a mano i coefficienti, cioè per esempio definendo che ognuno di questi 3 dati potesse costituire il 33% dell'importanza del punteggio finale.
Ciò che vogliamo fare ora è quindi espandere la base dei dati e dire al motore di intelligenza artificiale in modo che trovi lui le correlazioni tra i dati di partenza e l'importanza delle email.
Tecnicamente i dati di partenza ottenuti dalla marcatura meccanica sono un set di dati supervisionati, perchè ad ogni email è stato dato un valore di importanza che fa da etichetta per ognuna di esse.
Lo schema generale è quello rappresentato in figura:
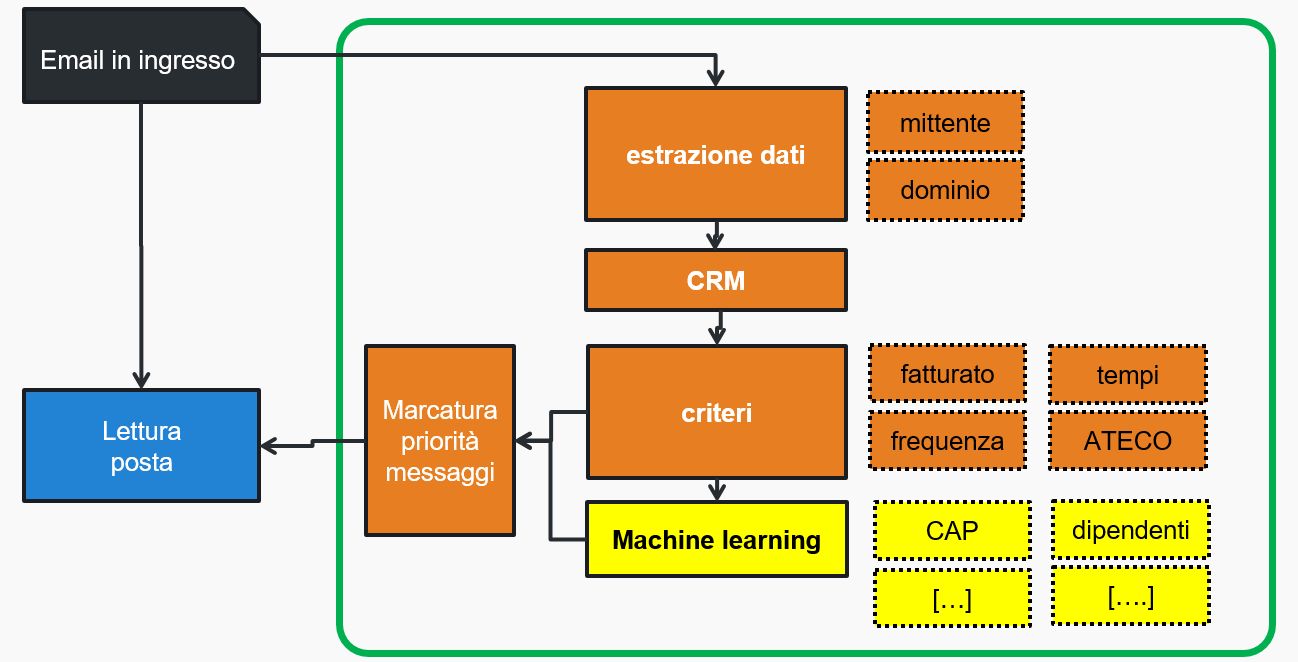
In giallo sono rappresentati a destra i dati 'in più' estratti dal CRM; capiremo più tardi a cosa possono servire.
Qui entrano in campo le competenze del data scientist o dell'esperto di intelligenza artificiale che dovrà rispondere a due domande:
- in base a questi dati di partenza quale algoritmo può essere utilizzato per effettuare la previsione di importanza delle email?
- quale soluzione tecnica si può proporre per applicare questo algoritmo ai dati di partenza?
Per rispondere alla prima domanda l'esperto dovrà decidere in base al tipo di dati (testi, valori numerici, eventualmente immagini, vettori multidimensionali etc) e di obbiettivo quale algoritmo di base vorrà utilizzare (alberi di decisione, classificatori bayesiani, macchine a vettori di supporto, ecc). E' un punto cruciale della realizzazione del sistema, dove troppo spesso si prendono decisioni affrettate. Una delle migliori soluzioni è, se possibile, quella di adottarne più di uno e confrontare per un periodo di prova i risultati prima di decidere quale utilizzare.
La risposta alla seconda domanda è più intrigante vista la molteplicità di soluzioni che vanno dall'utilizzo di un semplice pc con software open source e procedure eseguite on-demand, o schedulate, all'utilizzo di sistemi di intelligenza artificiale distribuiti come quelli di Google, Amazon, Microsoft connessi tramite API e con risposte in tempo reale.
I parametri che guideranno nella scelta sono quelli relativi ai tempi di risposta e al numero di email da analizzare nell'unità di tempo, cioè in base alle prestazioni richieste.
A questo punto il nostro motore potrà riservarci delle sorprese perchè l'indicazione della importanza delle email non sarà più dovuta ai parametri 'meccanici' che abbiamo impostato nella prima fase, ma sarà il motore stesso a decidere quali parametri utilizzare. Ovviamente, visto che l'abbiamo istruito su quei parametri, in un primo tempo ci risponderà esattamente come il sistema meccanico; tuttavia potrebbe 'accorgersi' che in realtà alcuni altri paramentri che gli abbiamo fornito sono più utili di quelli che abbiamo impostato, o che la contemporanea concomitanza di due dati apparentemente non correlati sia in realtà importante per definire la priorità.
Se, per esempio, un particolare distretto industriale riceve per le aziende presenti sul suo territorio un finanziamento particolare per le lavorazioni di cui alle richieste di preventivo, il motore di intelligenza artificiale si 'accorgerà' dell'importanza del CAP nel definire il 'successo' delle email e aggiusterà di conseguenza i parametri per definire le priorità. Non saremmo mai riusciti, a 'mano', ad inserire questo parametro e difficilmente ce ne saremmo accorti dell'importanza, ma il sistema 'intelligente' lo può fare.
Di qui discende l'importanza di 'nutrire' di molti dati il sistema ed è per questo che nel collegamento con il CRM sono stati estratti tutti i dati a disposizione.
Fase 4: la rivincita dell'umano
Come anticipato, il motore di ia può sbagliare, cioè definire priorità che in realtà non lo sono e, viceversa, non indicare come prioritarie email che lo sarebbero.Ciò vuol dire che dai dati che gli abbiamo messo a disposizione il motore non riesce ad estrarre maggiore conoscenza sulle priorità. L'unico metro che ha per decidere se una email è valida è la 'etichetta' del set di dati supervisionato, cioè il punteggio di importanza dato dal sistema meccanico.
Ma a questo punto il punteggio di importanza è il sistema stesso che se lo definisce, 'se la canta e se la suona' con il rischio di un cortocircuito logico; dà come prioritarie le email che lui stesso definisce prioritarie. E' necessaria una correzione di rotta.
Proprio per questo è previsto un meccanismo con il quale le persone che quotidianamente interagiscono con queste email possano 'bacchettare' il motore di intelligenza artificiale, cambiando il 'voto' di priorità dato alle email; cambiando l'etichetta del dato supervisionato il motore deve adeguarsi a queste nuove indicazioni, utilizzando le correzioni per raffinare la previsione di priorità.
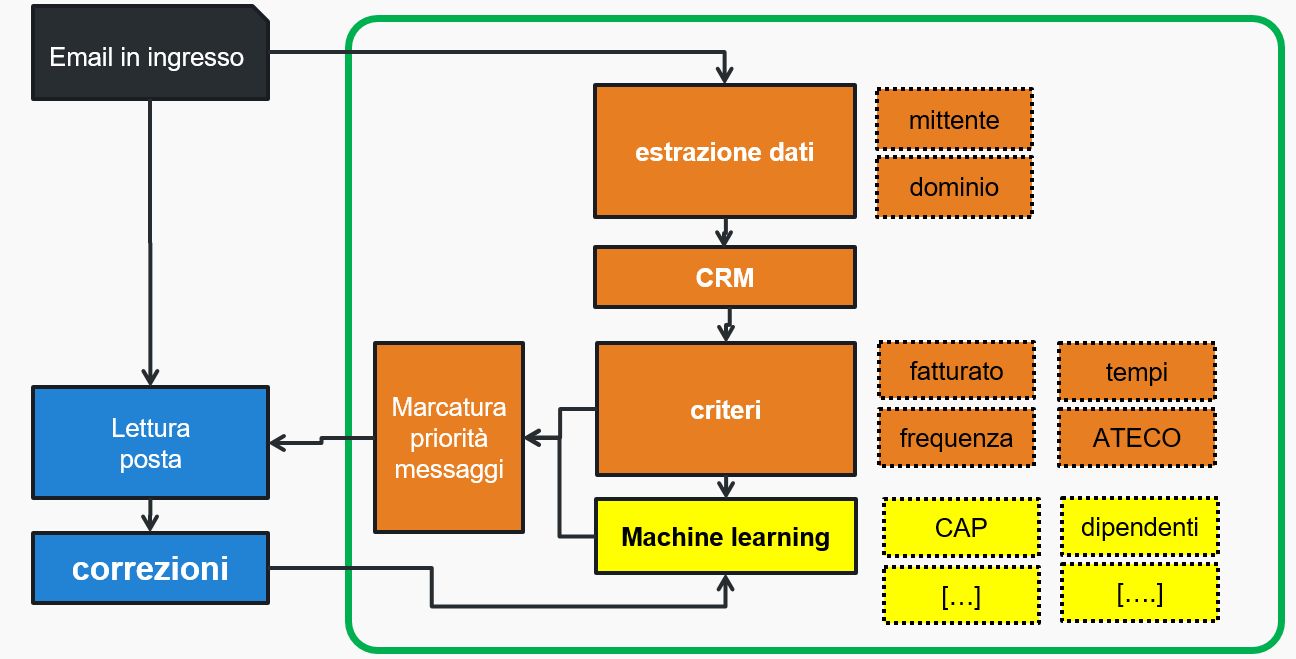
Fase 5: espansioni con algoritmi semantici
Nel caso reale della implementazione eseguita l'algoritmo utilizzato consente di utilizzare stringhe e valori numerici.
Vogliamo ora spingerci oltre cercando di utilizzare anche il valore semantico dei testi che abbiamo a disposizione: oggetto e corpo del messaggio, in modo da poter dare al nostro motore di intelligenza artificiale anche la possibilità di 'capire' da ciò che è scritto in questi testi se l'email sia importante oppure no.
Gli algoritmi che cercano di capire il valore semantico di un test vanno in genere sotto il cappello della sigla NLP, natural language processing; anche in questo caso sarà il data scientist o l'esperto IA a definire quale utilizzare. Essenzialmente possiamo elencare quelli pre 2013 e quelli post 2013, mettendo come data di separazione quella di invenzione di algoritmi evoluti di semantizzazione che trasformano il significato del testo in valori numerici.
Nel primo caso (pre 2013) troviamo algoritmi utilizzabili tipo LDA, Latent Dirichlet Allocation; lavora sulle posizione delle parole nel testo e, dandogli in pasto per esempio tutti i testi delle email, è in grado di evidenziare gli n argomenti principalmente contenuti melle email e 'battezzare' ogni email con il relativo argomento.
Se n è pari a 30, per esempio, tutto l'insieme dei testi di tutte le email viene analizzato e ne vengono estratti i trenta argomenti principali contenuti; quindi, per ognuna delle email, si evidenzia qual sia l'argomento principale, quale quello secondario e così via via fino a quello o a quelli non rappresentati.
Questi dati vengono visti come un insieme di dati supervisionati (l'etichetta è la vicinanza agli argomenti) che il motore di intelligenza artificiale può utilizzare ad esempio verificando che un certo argomento è quasi sempre presente nelle email più importanti e quindi associarlo ad un buon punteggio di priorità.
Nel secondo caso (post 2013) si utilizzando gli algoritmi di vettorializzazione semantica che trasformano il significato di un testo in un vettore multidimensionale in qualche modo 'matematicizzando' la conoscenza; esattamente come nel caso precedente questi vettori multidimensionali possono essere dati in pasto ad un motore di intelligenza artificiale che 'capirà' quali sono i valori semantici (= il significato delle email) meglio associabili ai migliori punteggi di priorità.
Ecco lo schema aggiornato:
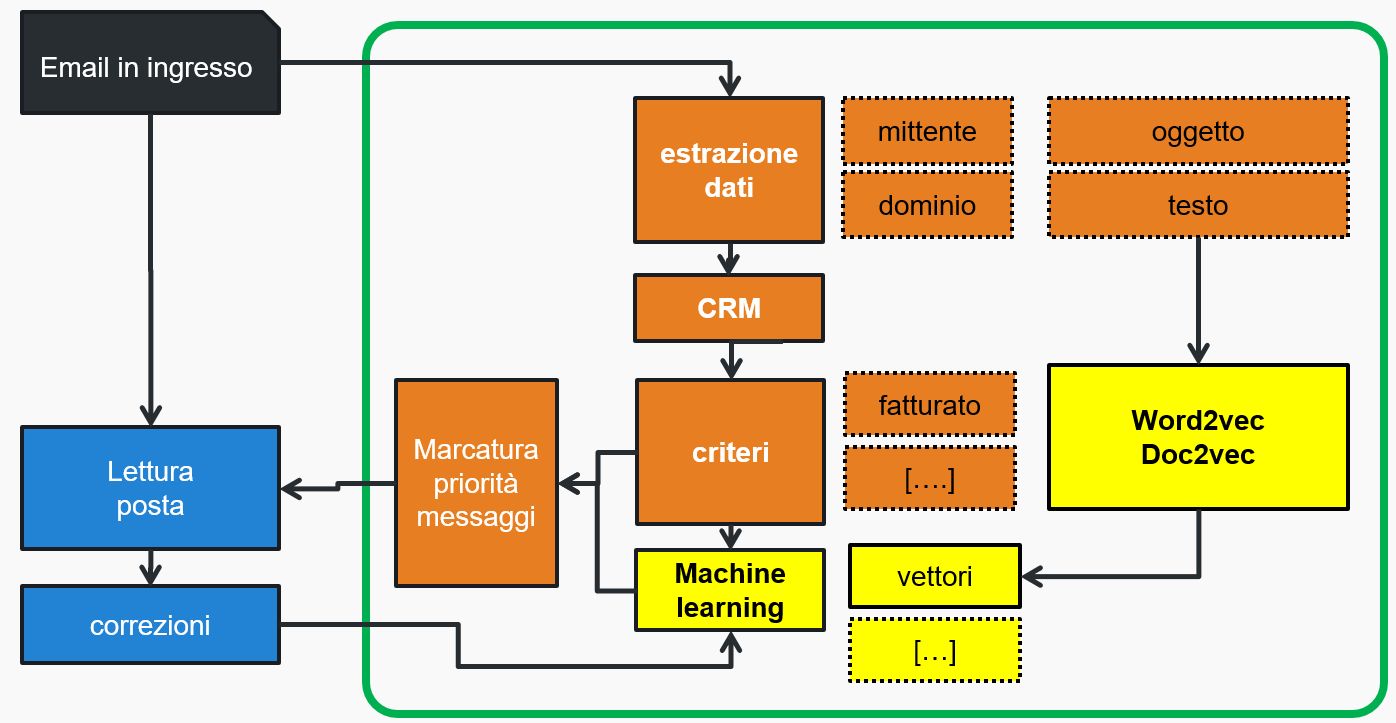
Gli algoritmi utilizzati sono word2vec che trasforma in vettori multidimensionali le singole parole con il loro significato e doc2vec che si comporta allo stesso modo con interi documenti (per esempio tutto il testo di una email).
Fase 6: espansione ai dati esterni all'azienda
Le email che possono essere analizzate fino a questo punto sono solo quelle che in qualche modo possono essere riferite ad aziende presenti nel CRM; nulla può essere detto per quanto riguarda le restanti email.
Possiamo procedere ad analizzare anche le email non ricollegabili al CRM in due modi:
1) utilizzando un subset di dati. Abbiamo a disposizione alcuni dati che non sono estratti dal CRM ma direttamente dalle caratteristiche dell'email: testo e lunghezza dell'oggetto e del corpo, presenza di immagini, e tutte le informazioni lessicali: sia LDA che word2vec/doc2vec ed eventualmente anche le analisi di frequenza e TF/IDF. Con questi dati possiamo istruire un motore di intelligenza artificiale parallelo ed integrato a quello prima descritto così da ottenere informazioni di priorità anche per queste email;
2) collegandoci a banche dati esterne tramite API; le banche dati delle camere di commercio, o altre simili, possono essere un buon appoggio per estrarre dati utlizzando il nome di dominio dell'email; in questo modo vengono estratti dall'esterno alcuni dei dati (numero dipendenti, grandezza, ateco, etc) che precedentemente venivano estratti dal crm. Non è da sottovalutare il valore arricchiente anche verso i dati già in nostro possesso, integrando le informazioni del CRM con quelle ottenute esternamente.
Esempio applicativo
La procedura qui illustrata è stata applicata ad un caso reale;i tempi di realizzazione sono stati dell'ordine dei tre mesi tra progetto ed implementazione.Il risultato è visibile in questa immagine:
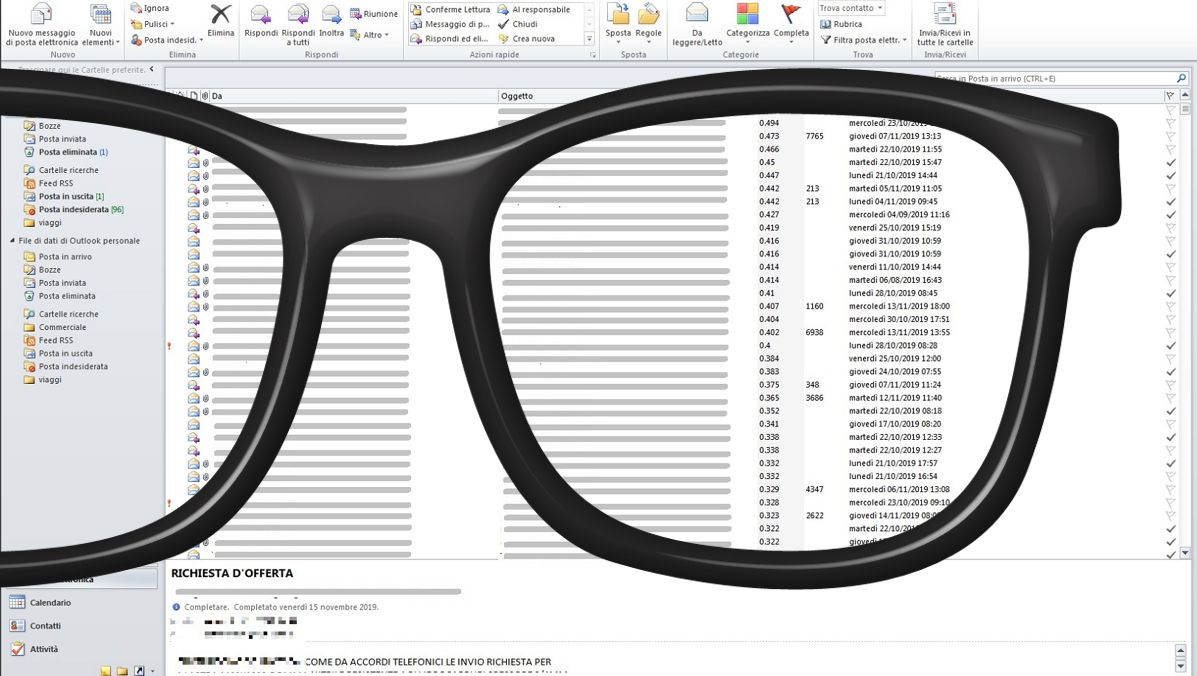
A fianco di ogni email, di cui sono stati oscurati i dati, si nota una colonna con valori da 0 ad 1 che indicano la priorità. In questo particolare sistema a fianco di questo valore c'è l'ID cliente interno dell'azienda, che consente di preimpostare l'offerta semplicemente cliccando sul valore.
Conclusioni
In questo articolo si è descritto un caso pratico di applicazione dell'intelligenza artificiale in azienda che classifica le email in ingresso predicendone il valore di importanza.
L'applicazione è in funzionamento e sta erogando i primi risultati che saranno oggetto di revisione e di successivo affinamento.
Dai primi dati si evince l'utilità del sistema installato e si ipotizza che l'autoregolazione che avverrà nel tempo lo renderà sempre più affidabile.
L'applicazione è avvenuta in una azienda dalle dimensioni contenute senza la necessità di utilizzare grandi capitali: poche decine di migliaia di euro possono essere sufficienti per andare anche oltre al sistema qui descritto.
Ciò dimostra come l'intelligenza artificiale sia alla portata di tutti e quanto sia possibile utilizzarla come driver per la crescita; dall'esperienza maturata si evince quanto sia necessario avere all'interno dell'azienda uno sponsor nel top management e qualche figura tecnica che possa dedicarsi al progetto.
Dogma Dynamics si propone come interlocutore per valutare quanto l'intelligenza artificiale possa entrare nei processi produttivi dell'azienda in casi come questo o in altri in cui la quantità di dati a disposizione sia sufficiente per innescare il meccanismo virtuoso dell'autoapprendimento con le macchine. In questo modo si riesce ad inserire effettiva innovazione in azienda evitando i lavori più ripetitivi (guardare tutte le email, anche quelle 'inutili' in questo caso) e ottimizzando l'utilizzo delle risorse umane verso compiti che siano veramente, e non artificialmente, intelligenti.