vendita auto: intelligenza artificiale e deep learning al servizio del marketing
L'intelligenza artificiale è costituita da una serie di algoritmi e metodi statistici che, tra le altre cose, consentono di analizzare dati in modo inimmaginabile precedentemente.
L'analisi del testo e del suo significato è uno degli ambiti nei quali si possono ottenere risultati innovativi; nel seguito viene descritta l'analisi della 'conoscenza' della rete per estrarre significati da testi relativi al settore delle concessionarie di vendita e noleggio auto.
In questo caso l'utilizzo è finalizzato alla promozione e al marketing; come si vedrà più avanti la metodologia è comunque estendibile ad applicazioni di diverso tipo.
Tecnicamente si procederà a mappare la conoscenza presente in rete per estrarre gruppi di termini analoghi per significato semantico; l'utilizzo di questi termini può essere effettuato all'interno del marketing mix (seo - ppc - social - display) per ottimizzare le campagne di promozione.
Nella parte finale vengono raccolti i risultati ed indicati i modi per utilizzarli che vanno al di là dello specifico settore delle auto per estendersi al marketing online ed in particolare ai sistemi ecommerce.
La ricerca della conoscenza in rete.
Ogni applicazione di intelligenza artificiale ha bisogno di dati sui quali allenare il modello; sono i 'big data' che quanto più sono grandi tanto più rendono affidabile il modello.
Nel caso in esame questi dati vengono desunti dal testo presente in pagine web relative al settore vendita e noleggio auto.
Per ottenere queste pagine:
- si parte da un elenco di 50 keyword definite da esperti del settore
- si analizzano le risposte di google (SERP, search engine position) per ognuna delle ricerche, fino alla 50ma posizione
- si scaricano tutte le (50x50) 2500 pagine di risposta
- da esse si ricava il testo necessario all'analisi, isolando il testo 'originale' dal contesto (tag, menu, etc)
- si eliminano gli eventuali doppioni e si esegue un prepocessing del testo, togliendo interpunzioni, numeri, parti del discorso (POS, part of speech) non utili, convertendo le maiuscole, etc
Ovviamente cambiando le keyword iniziali l'analisi si può effettuare su qualsiasi argomento, il procedimento risulta lo stesso; l'integrazine con metodi di definizione delle keyword più elaborati (ad esempio partendo da Google Trends, Adwords, Search Console) può portare ad indagini più mirate allo scopo.
L'analisi della conoscenza.
A questo punto il corpus opportunamente preprocessato può essere dato in pasto all'algoritmo di word embeddings 'word2vec' che si incarica di trasformare ogni parola presente nel corpus nella sua rappresentazione vettoriale matematica; questa rappresentazione sarà alla base dei trattamenti che potranno essere effettuati sulle parole.
Definiamo alcuni parametri necessari al funzionamento dell'algoritmo:
- la finestra di contesto, cioè lo spazio di parole intorno a quella analizzata. Nella frase precedente 'cioè lo spazio di parole intorno a quella analizzata', per il termine 'spazio' se la finestra di contesto vale 5 il termine 'cioè' è distante -2, 'lo' -1, 'di' +1, 'parole' +2. In questo modo abbiamo definito i valori delle parole vicine a 'spazio'. Spostando in avanti di una posizione la finestra di contesto lo stesso viene ripetuto per tutte le parole del corpus.
- il parametro che decide quali parole analizzare e quali no. L'algoritmo richiede risorse per funzionare, è bene limitare il numero di parole sul quale farlo funzionare. Nel nostro caso limitiamo lo studio alle parole che appaiono almeno 20 volte nel corpus dei documenti.
- il numero di dimensioni dello spazio di rappresentazione vettoriale delle parole: viene impostato a 100, più avanti ne verrà spiegato il significato.
Come abbiamo visto ogni parola del corpus è in rapporto con le altre parole; prima è stato visto che la parola 'spazio' è in rapporto +2 con il termine 'parole' e -1 con 'cioè'.
Lo stesso termine 'spazio' probabilmente si troverà in altre frasi nel corpus; in tal caso sarà in rapporto diverso con altre parole.
Possiamo in questo modo definire una matrice, o una tabella, con un numero di righe pari al numero di parole ed un numero di colonne altrettanto grande; ogni riga rappresenta una parola ed ogni colonna anch'essa una parola.
All'incrocio tra righe e colonne troveremmo, per qualsiasi combinazione di parole, il valore medio di tutte le volte che in qualche modo si sono incontrate in una finestra di contesto.
Nel caso descritto il numero di parole analizzato è 3208; queste sono le parole trovate nel corpus dei documenti almeno 20 volte, quindi la tabella o matrice descritta è di 3208 righe per 3208 colonne.
A questo punto interviene il concetto di spazio dimensionale e l'implicazione delle reti neurali.
Attraverso una rete neurale di deep learning viene cercato per successivi tentativi, aggiustamenti e retroazioni per ogni parola un vettore a 100 dimensioni che rappresenti nel miglior modo possibile la posizione della parola in esame rispetto a tutte le altre 3207.
Ovviamente se avessimo scelto uno spazio dimensionale di 500 avremmo 500 valori dimensionali o 'attributi numerici' della parola che nel loro insieme descrivono un vettore, aumentando la precisione con la quale viene definito.
Se ogni parola viene rappresentata nello spazio della conoscenza da un vettore multidimensionale che ne esprime i rapporti con tutte le altre parole del corpus, ne potrà discendere che due paole aventi un vettore dimensionale molto simile saranno due termini semanticamente simili, cioè con significato analogo, perchè in simile rapporto con le altre parole; a questo punto è chiara la 'magia': abbiamo trasformato una serie di testi in una rappresentazione di parole legate tra loro ad esprimere un significato; la lettura da parte di una macchina diventa una lettura 'intelligente' perchè in grado di inserire le parole all'interno di un contesto semantico.
In termini matematici, più piccola è la distanza tra i vettori che rappresentano due parole e più simile sarà il loro significato.
Naturalmente non riusciamo a farne una rappresentazione visiva di uno spazio a 100 dimensioni; ma possiamo ragionarne in uno spazio tridimensionale che è alla nostra portata per estendere le considerazioni a quello multidimensionale.
Possiamo immaginare che nello spazio tridimensionale ogni parola sia rappresentata da un vettore a tre dimensioni che sono le tre componenti spaziali; in questo modo ogni parola verrà rappresentata da un punto nello spazio tridimensionale, e due parole appariranno come due punti nello spazio.
Se ogni parola nel corpus può essere rappresentata da un punto otterremo 3208 puntini rappresentati nello spazio tridimensionale.
La 'magia' in questo caso è rappresentata dal fatto che due puntini vicini nello spazio saranno anche due puntini vicini come significato semantico; cercando tutti i puntini 'vicino' ad una certa parola otterremo le parole che le sono vicine come significato.
Naturalmente passando dalle 100 dimensioni alle tre dimensioni perdiamo molta informazione, ma otteniamo una rappresentazione a noi più consona; possiamo anche pensare ad una rappresentazione su due dimensioni, rendendo ancora più semplice la visione.
Tutto questo è possibile 'riducendo' lo spazio multidimensionale impercepibile visivamente ad uno spazio a due o tre dimensioni; tramite l'algoritmo PCA (Principal Component Analysis) possiamo ottenerlo e passare a qualche rappresentazione grafica.
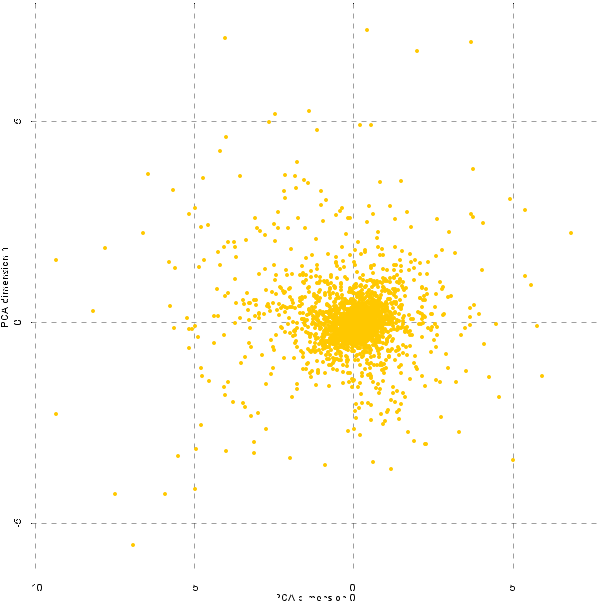
Questa la rappresentazione bidimensionale delle parole presenti nel corpus; naturalmente non ci dice molto, se non che tutti i termini si addensano in una zona comune.
Possiamo cercare di capire quanto la nostra rappresentazione sia effettivamente 'riuscita' cercando di puntare su una specifica parola per vedere quali siamo quelle ad essa più vicina.
Per esempio se puntiamo sulla parola scelta a caso 'tergicristalli' possiamo misurare tutte le distanze esistenti tra il vettore di questa parola e i vettori delle restanti; rappresentanto questa distanza come colore indicheremo con il rosso le parole vicine:
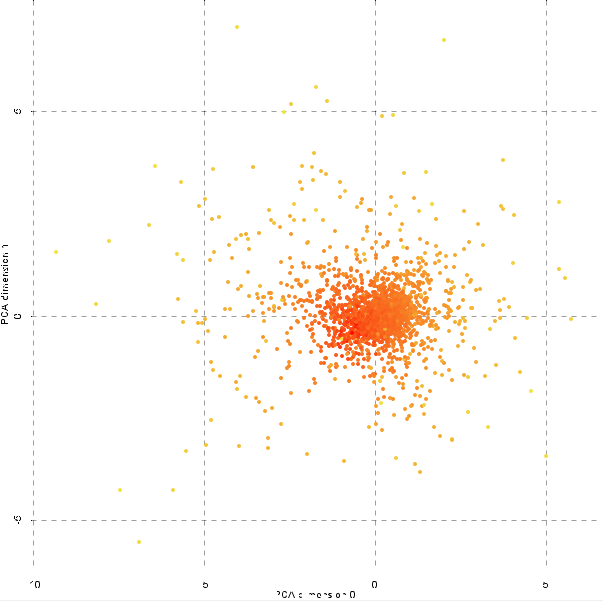
Vediamo ora che una certa zona dello spazio della conoscenza, in basso e a sinistra rispetto alla nuvola dei punti, è quella rappresentata dai termini più vicini a 'tergicristallo'.
Possiamo interrogare le nostre tabelle per estrarre quali siano questi termini vicini per vettore, eccoli ordinati per distanza crescente:
| esterne |
| spazzole |
| interne |
| distribuzione |
| carica |
| lavavetri |
| sterzo |
| esterna |
| fluidi |
| ispezione |
| dispositivo |
| dischi |
| impurità |
| ammortizzatori |
| liquidi |
| stabilità |
effettivamente i termini sono correlati con il concetto di tergicristalli, anche se alcuni (ammortizzatori?) sembrano meno vicini; teniamo conto del valore indicativo e didattico di questa ricerca.
Proviamo a visualizzare lo stesso grafico con una riduzione dimensionale a tre e rappresentando i punti nello spazio tridimensionale:
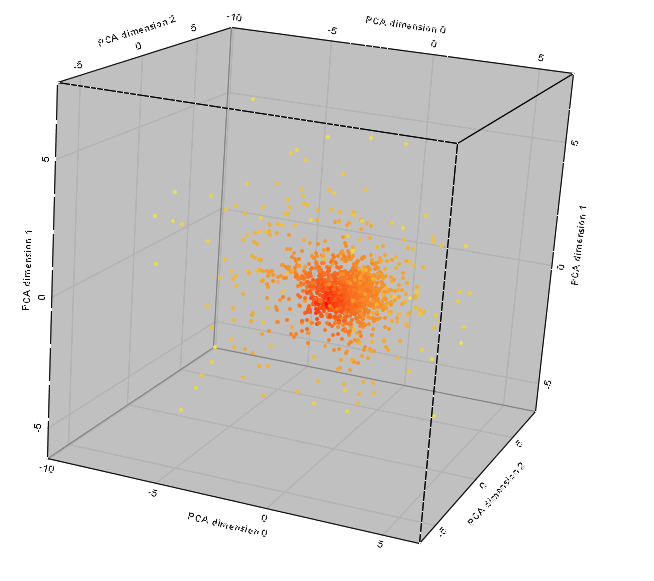
Rimane ancora più chiaro quanto la zona 'tergicristalli' sia effettivamente una parte della nuvola dei punti localizzata in modo definito.
Per testare meglio il funzionamento dell'algoritmo proviamo ad indagare la posizione dei termini facendo perno su più parole; oltre a 'tergicristalli' cerchiamo di rappresentare lo spazio dimensionale dei significati di:
| assicurazione |
| cabrio |
| spider |
| quotazione |
| quattroruote |
| bollo |
| garanzia |
| rottamare |
| tergicristalli |
I termini correlato semanticamente diventano:
| assicurazione | bollo | cabrio | garanzia | manutenzione | quattroruote | rottamare | tergicristalli |
| polizza | imposta | ferrari | legale | tagliando | kijiji | corrispondere | esterne |
| incendio | incendio | duster | qualsiasi | riparazione | potere | potresti | spazzole |
| furto | prestito | partono | furto | effettuare | singole | singola | interne |
| cliente | interessi | zafira | conformitã | sostituzione | confrontare | molteplici | distribuzione |
| prestito | garanzie | countryman | incendio | veicolo | notare | dell'offerta | carica |
| garanzie | dovuto | outlander | veicolo | dell'auto | veritã | all'estero | lavavetri |
| mezzo | assicurazione | 1368cc | difetti | controlli | conta | risponde | sterzo |
| terzi | eventi | arrivo | garanzie | libretto | francia | confrontare | esterna |
| risarcimento | pratica | iveco | richiesta | ordinaria | rottamare | ipotesi | fluidi |
| pagare | richiedere | diventano | risarcimento | necessario | professionali | scooter | ispezione |
Rappresentiamo ogni parola delle 3208 con un colore diverso a seconda della 'parola perno' di quelle sopra riportate a cui fa riferimento e con un punto tanto più grande quanto più piccola è la distanza, dapprima nello spazio bidimensionale:
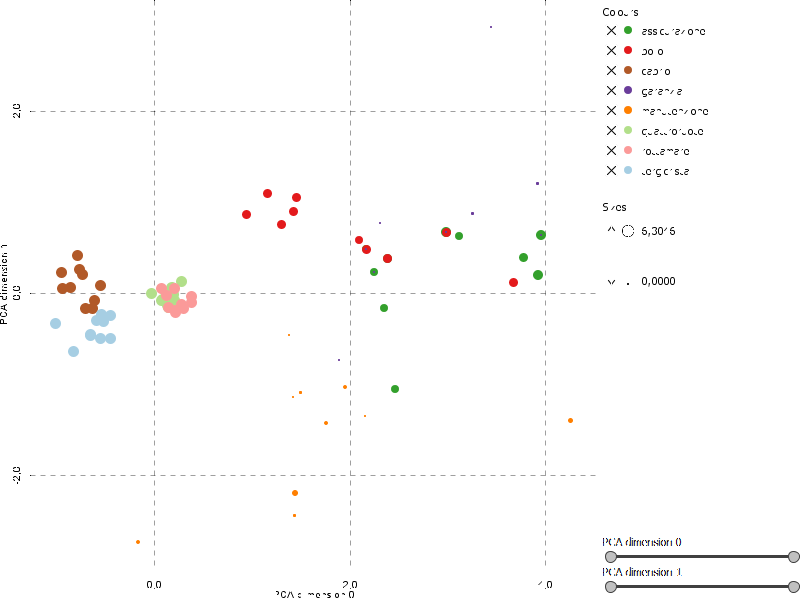
E quindi in quello tridimensionale:
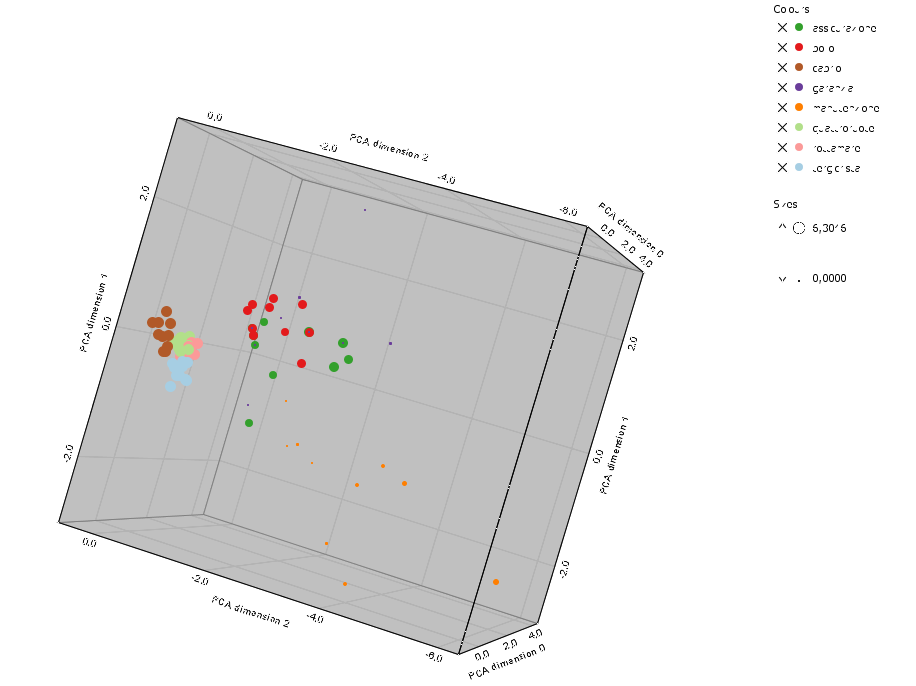
abbiamo limitato il numero di punti considerati, prendendo i 10 punti più vicini.
Se passassimo ai 100 punti più vicini la rappresentazione diventerebbe:
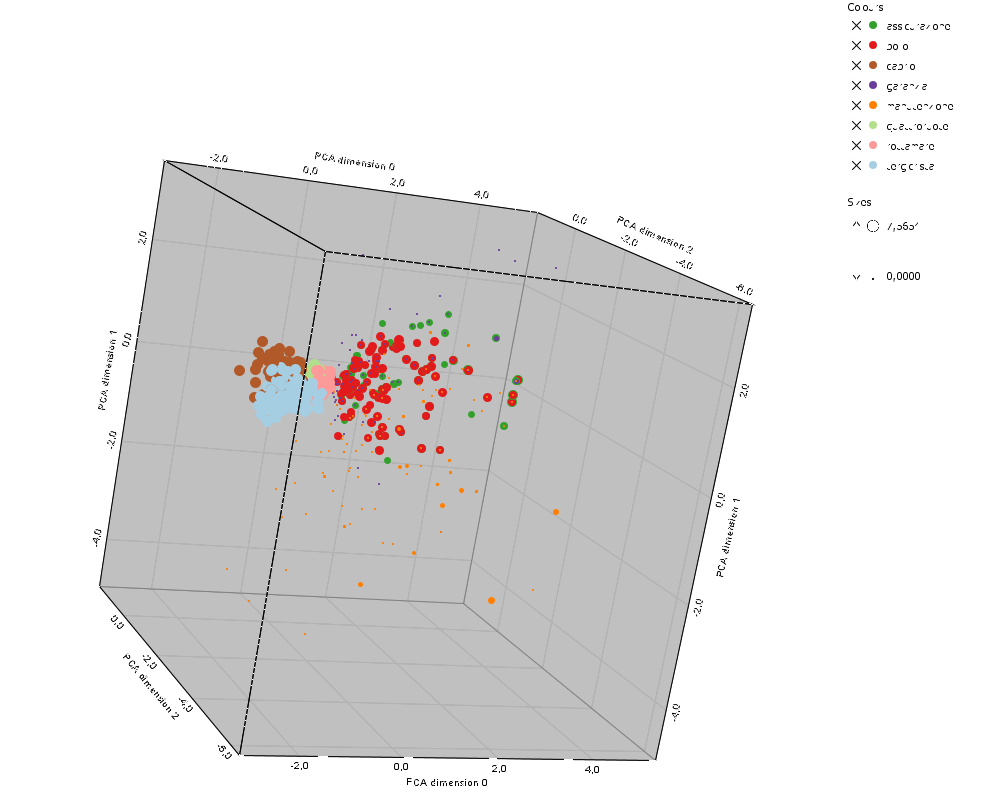
Possiamo ancora meglio notare come qualche concetto sia caratterizzato da termini molto vicini (tergicristalli, cabrio, rottamare) mentre altri hanno solo termini 'dispersi' nello spazio semantico (manutenzione) perchè relativi a diversi significati.
Bene... bei grafici.. ma a che serve?
Innanzitutto a dimostrare come si possa 'matematicizzare' il significato dei testi, in modo da interrogare contenuti testuali in modo impossibile prima del word embedding, che è un algoritmo di intelligenza artificiale scoperto da pochi anni e che quindi consente applicazioni innovative in settori diversi.
Questi grafici possono servire a dare una idea di ciò che si può fare; ogni singola applicazione può approfondire il metodo con cui utilizzarli.
Oltre al word2vec si può utilizzare il doc2vec che tratta i documenti allo stesso modo con il quale in questa pagina sono state trattate le parole, convertendoli cioè in vettori nello spazio multidimensionale; in tal caso i puntini dello stesso colore sarebbero documenti simili, consentendo una analisi a livello di documento simile a quella condotta a livello di parole.
Integrazione dell'intelligenza artificiale nel marketing online
Questa analisi risulta molto utile quando è necessario utilizzare termini correlati al significato di un termine principale; possiamo citare alcuni esempi:- nel caso di advertising di tipo PPC può essere utile per scovare termini con pari significato semantico ma meno costosi, diminuendo la spesa necessaria per le campagne
- nel caso di copywriting può essere utile per definire i termini da utilizzare per scrivere contenuti utili all'indicizzazione
Risultati più precisi possono essere ottenuti abbinando al sistema descritto un lemmario che riporti ogni termine alla sua radice; in questo modo, per esempio, ogni aggettivo verrebbe portato alla sua radice eliminando le variazioni di genere e di persona, così ogni sostantivo e verbo, ottenendo una lista 'pulita' vi sostantivi, verbi e aggettivi utilizzati nel settore analizzato ed organizzandoli a seconda dell aloro vicinanza.
Questa lista correlata ai posizionamenti potrebbe suggerire gli argomenti da affrontare nei settori copywriting e social per scrivere interventi e contenuti con una più alta probabilità di buon posizionamento.
Con tecniche di Natural Language Composition potrebbero essere scritti automaticamente contenuti a partire dalla conoscenza acquisita; di questo scriverò in un prossimo articolo.
Integrazione dell'intelligenza artificiale nei siti ecommerce
Ottenere parole semanticamente correlate può essere utilizzato all'interno di sistemi ecommerce in modo da aumentare il tasso di conversione, gli esperimenti effettuati sono stati condotti in Dogma Dynamics in due direzioni: utilizzandoli all'interno di un motore di ricerca semantico e nella creazione degli articoli correlati.Nel primo caso si aiuta l'utente a cercare ciò che desidera: inserendo un termine all'interno del motore di ricerca interno al sito ecommerce non solo vengono cercati gli articoli che corrispondono alla parola cercata ma anche quelli che corrispondono a parole semanticamente vicine, suggerendo tra i riusltati non solo quanto è direttamente connesso con la parola cercata ma anche tutto ciò che riguarda parole semanticamente simili, allargando le possibilità dell'utente di incontrare articoli potenzialmente utili alla propria ricerca.
Da stime presenti in rete si desume che un motore di ricerca semantico aumenta del 20%/30% il tasso di conversione; esperimenti personalmente condotti su siti ecommerce indicano un aumento anche maggiore.
Come Dogma Dynamics il prodotto dogmaSearch è oggetto di una linea di sviluppo di motori semantici per siti ecommerce che vanno esattamente in questa direzione, utilizzando altri (big) dati utili come l'analisi delle navigazioni di tutti gli utenti per potenziare ulteriormente il motore di ricerca con risultati di provata positiva azione sulle vendite.
Nel secondo caso si tratta della creazione del 'carousel' e dell'elenco dei 'correlati', cioè tutti quei prodotti che non sono direttamente ricercati dall'utente ma sono collegati semanticamente.
In grandi ecommerce è praticamente impossibile inserire per ogni prodotto la lista dei correlati; in questo modo l'analisi con intelligenza artificiale li individua e li mette in relazione indicando per ognuno una serie di 'ti potrebbe interessare anche...' che è di esperienza quotidiana sui grandi portali di vendita.
Anche in questo caso l'integrazione con l'analisi delle navigazioni degli utenti può portare a suggerire tra i correlati quei prodotti a vendita più certa che contribuiscono ad aumentare il tasso di conversione.
Conclusione
L'intelligenza artificiale sta muovendo i primi passi nelle applicazioni pratiche; in questo articolo si è utilizzato il deep learnig su word embeddings per estrarre relazioni semantiche tra parole utili al marketing ed implementabili su siti ecommerce per ottenere un aumento delle conversioni.
L'utilizzo di questi metodi unito alla specifica conoscenza di settore può dare risultati diretti nell'incremento delle vendite venendo incontro alla domanda espressa dall'utente con le proposte dei venditori, indipendentemente dal settore merceologico.
In questo modo ne ottiene un vantaggio sia l'utente che trova più facilmente ciò che cerca che il venditore che presenta in modo più smart i propri prodotti, sia a livello di ecommerce che di proposta generale di marketing.
Va sottolineata la necessità di comprendere a fondo, da parte dei project manager, i meccanismi di funzionamento per non incorrere nel rischio di acquistare 'pacchetti' di cosidetta 'intelligenza artificiale' senza ben saperne lo scopo e quindi non ottenendone i vantaggi.
E' necessaria una implementazione consapevole per sfruttare le potenzialità che l'intelligenza artificiale può inserire nei sistemi di analisi, promozione e vendita online.
Italo Losero